Pinning a sensor's error without a reference: how many co-recorded windows, and how long each, for three-cornered-hat σ across an O2Ring · Polar H10 · Verity Sense trio
PpgDex (raw PPG) · ECGDex (raw ECG) · OxyDex nodes, Tepna physiological-signal suite
Abstract
Background. The companion paper (sigma-no-reference) shows that a per-device heart-rate error σ can be recovered with no calibrated reference via a three-cornered hat (TCH) over a simultaneous O2Ring + Polar H10 + Verity Sense window. But its noisiest corner rested on a single overlap window — a point estimate with no confidence interval. This paper answers the practitioner's question instead: how many co-recorded trio-windows do you actually need to pin each device's σ to a usable precision? It is the device-metrology analog of nights-icc — there, how many nights to pin a person's metric; here, how many windows to pin a sensor's error. Methods. A synthetic trio generator emits 1-Hz "true HR" per window in two variance regimes — resting (small true variance) and dynamic (exercise/recovery ramp) — plus three sensors = truth + independent noise with planted σ set to the real estimates (1.7 / 2.2 / 6.2 bpm). The same per-window TCH kernel and cross-window aggregation the σ-paper uses are driven over N_windows ∈ {1,2,3,5,8,12,20} with 720 Monte-Carlo trials per cell; an injected pair-wise error correlation ρ calibrates the assumption test. A single co-recorded window, scored by the production raw-signal detectors (Verity HR ← raw PPG via PPGDSP; H10 HR ← raw ECG via Pan–Tompkins), is laid beside the simulation band as an anecdotal check. Results. One ~1-hour trio-window pins every device σ to ≈±0.5 bpm in the clean (dynamic) regime (H10 and Verity just under it, O2Ring right at the line); ±0.25 needs ~5–8 windows and ±0.15 needs ~12–20. Window length trades against count: at a single window ~1 hour is the floor to reach ±0.5 bpm (AR(1)-autocorrelated error caps the effective samples), so finer precision comes from more windows, not longer ones. Because the hat couples the trio, the noisy Verity corner sets a shared precision floor, so absolute CI half-widths are similar across devices rather than far worse for the noisy one. The regime cost is bias, not window count: the dynamic regime recovers each true σ (bias ≈0); the resting regime recovers only the independent-error floor, under-stating the instantaneous devices (H10 −0.47 bpm, −21%; Verity −0.17 bpm) because the TCH strips the shared beat-to-beat HRV. A correlated-error failure is undetectable below a few windows (ρ=0.15 caught ~4% at N=1, ~53% by N=20; ρ≥0.3 nearly always). The one committed real window recovers 1.67 / 2.17 / 6.22 bpm, matching the planted totals and bracketing them within block-bootstrap CIs. Conclusion. Report σ only with N_windows and a CI; one clean dynamic window pins the trio to ±0.5 bpm, but resting nights buy precision while quietly biasing the answer — a non-resting session is what makes the assumption hold and recovers the full σ. This is a fully synthetic power result under stated noise assumptions; the single co-recorded window is shown only as an anecdotal sanity check (not a validation cohort), and the conclusions rest entirely on the simulation.
Keywords: measurement uncertainty · sample size · statistical power · three-cornered hat · reference-free metrology · Monte-Carlo · heart rate · wearables · raw PPG / ECG
0. Layman overview (delete before submission)
Every sensor that reports your heart rate is a little bit wrong. A companion study showed a neat trick: wear three different devices at once and you can measure how wrong each one is without any lab "truth" machine — the three disagreements, taken together, reveal each device's own error. The catch is that one night of doing this gives you a single guess with no error bars. So the practical question here is: how many nights of wearing all three do you need before you can trust each device's wrongness number?
Using simulated nights where we know the true answer, with one real recorded night shown alongside as an anecdote, we found: one ~hour-long session already pins each device to within about half a beat; getting twice as precise takes five to eight sessions. A surprising part: the trick works best on a moving night (a walk plus recovery), not a still resting night — on a perfectly still night the math quietly under-counts the chest strap's and armband's error. And below a few sessions you can't even tell whether the three devices are failing together (which breaks the trick) or just being noisy. The headline: never quote a device's error without saying how many nights it came from. (The recipe is proven entirely in simulation; the single real night is just an anecdote that happens to agree.)
So how many minutes do you actually need?
- A usable read (±0.5 bpm): about one hour of wearing all three at once, roughly continuous — a short clip is almost useless (1 min ≈ ±2 bpm, 10 min ≈ ±1 bpm, 60 min ≈ ±0.5).
- A tight read (±0.25 bpm): a few hours total — about 5–8 one-hour sessions, ideally on different nights, with at least one that includes movement (a walk + recovery), which is worth several resting hours.
- Not worth it: under ~30 minutes; and you can't reach ±0.25/±0.15 from any single sitting — that precision comes from more sessions, not a longer one.
Bottom line: ~1 hour minimum for a ballpark, a handful of hours for a precise number.
1. Introduction
A number a sensor reports is only as useful as the uncertainty attached to it, and the companion paper Measuring a device's σ without a canonical reference established how to obtain that uncertainty with no laboratory standard: the three-cornered hat (TCH), in which three devices measuring the same true heart rate let each device's own error variance be recovered from the three pairwise difference variances. That paper's weak corner was the Verity Sense, whose σ rested on a single ~2-hour overlap window — a point estimate with no confidence interval and no way to test the method's core assumption that the three devices' errors are uncorrelated.
This paper turns "one window" into "how many windows do you need." It is the metrology twin of How many nights?: that paper asks how many nights make a person's metric a reliable trait (ICC, Spearman–Brown); this asks how many trio-windows pin a sensor's error σ (TCH CI versus N). The unknown is different — there it is the between- vs within-subject variance of a metric, here it is the measurement-error variance of an instrument — but the deliverable is the same shape: a curve of precision against the number of occasions and a minimum-N recommendation. Two features make it more than a rehash. First, regime dependence: the TCH's variance estimates behave differently when the true HR variance is small (resting) versus large (dynamic), so the answer is "how many nights of what kind." Second, assumption-testability: a negative recovered variance is the tell of correlated device errors, and "how many windows before that failure is even checkable" is itself a result. The result is fully synthetic (the planted ground truth is what makes the answer defensible), and a single co-recorded real window is included only as an anecdotal comparison, not a validation cohort.
2. Methods
2.1 Synthetic trio generator (the power arm)
A small dedicated generator (in sensor-trio-power-analysis.js; it does not touch cohort-gen.js) builds, per window, a synthetic 1-Hz "true HR" series of realistic length (≈3,600 s) under a controllable variance regime: resting (slow drift, small true variance) and dynamic (an exercise/recovery ramp, large true variance). Three sensors are then formed as truth + independent Gaussian noise with planted per-device σ fixed to the paper's real estimates — σO2Ring=1.7, σH10=2.2, σVerity=6.2 bpm — with an AR(1) component (φ=0.9) so the noise is temporally correlated like a real residual rather than white. A shared beat-to-beat HRV term (the physiological signal the instantaneous devices track and the smoothed O2Ring partly averages out) is layered on truth; an optional injected error correlation ρ between a device pair calibrates the assumption test.
2.2 Estimator under test — the same TCH kernel
The estimator is the unmodified per-window TCH kernel and cross-window aggregation built for the σ-corner work and reused verbatim from sigma-no-reference-analysis.js — for three devices A, B, C with pairwise difference variances VAB, VAC, VBC:
a negative output flags a broken independence assumption. For each N_windows ∈ {1,2,3,5,8,12,20} we draw N windows, recover each device's σ̂, and repeat 720 Monte-Carlo trials per cell, reporting the bias of σ̂ (vs the planted total for that regime) and the 95% CI half-width across trials. We tabulate the minimum N to reach target half-widths of ±0.5, ±0.25, and ±0.15 bpm, sweep the injected ρ ∈ {0, 0.15, 0.3, 0.5, 0.7} for the assumption test, and run the whole grid under both regimes.
2.3 Anecdotal real-data comparison
The anecdotal real comparison uses the trio windows produced by the σ-corner derivation pipeline (SIGMA-WINDOW-DERIVATION.md): Verity HR derived from raw PPG with the production PPGDSP.analyze (SQI-gated), the H10 gold leg derived from raw ECG by Pan–Tompkins QRS (ECGDSP), the O2Ring native per-second pulse, all aligned on the Clock Contract's floating-ms grid. These detectors are run, not modified — this is an analysis tool, so no node is re-bundled and no provenance moves. The single committed window's σ̂ ± CI is laid beside the simulation's predicted 1/√N band as an anecdotal check (with the H10↔O2Ring leg as a built-in control); it is illustrative, not a validation set, and the paper's conclusions do not depend on it.
3. Results
3.1 One clean window pins the trio to ±0.5 bpm; the corners are coupled
In the dynamic regime σ̂ is essentially unbiased at every N (bias |·| ≤ 0.06 bpm), so precision is governed entirely by the CI half-width, which shrinks as ~1/√N (Figure 1). A single ~1-hour window pins H10 and Verity just under ±0.5 bpm and O2Ring right at the line (≈0.50); ±0.25 needs roughly 5–8 windows and ±0.15 needs 12–20 (Table 1). The non-obvious finding is that the half-widths are similar across devices in absolute bpm despite Verity's far larger σ: because the TCH solves the three corners jointly, the noisy Verity corner injects variance into all three pairwise differences and sets a shared precision floor. The practical consequence overturns the naive expectation — it is not "the noisy device needs far more windows"; the whole trio is pinned together, paced by its worst corner.
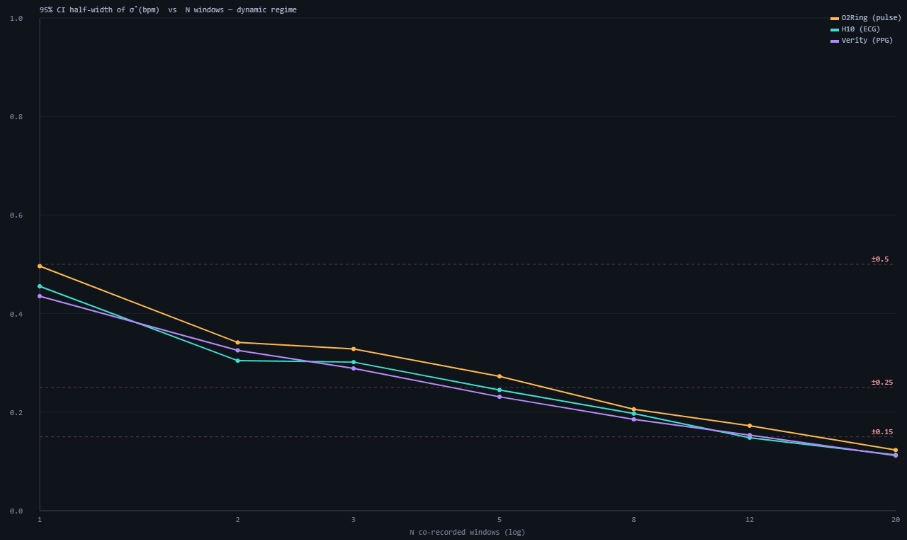
sensor-trio-power-analysis.html, 720 Monte-Carlo trials/cell). All three corners (O2Ring amber, H10 teal, Verity violet) track a common ~1/√N curve (dashed reference) and clear ±0.5 bpm by a single window; the ±0.25 and ±0.15 targets are marked. Dark theme is the tool's native rendering.| Device | Planted σ (bpm) | ±0.50 bpm | ±0.25 bpm | ±0.15 bpm |
|---|---|---|---|---|
| O2Ring (pulse) | 1.7 | 1 | 8 | 20 |
| Polar H10 (ECG) | 2.2 | 1 | 5 | 12 |
| Verity Sense (PPG) | 6.2 | 1 | 5 | 20 |
| Worst across devices | — | 1 | 8 | 20 |
3.2 The regime cost is bias, not window count
Switching from a dynamic to a resting truth does not meaningfully change the CI half-widths — it changes the bias of what the hat recovers (Figure 2, Table 2). In the dynamic regime σ̂ recovers each device's true total error (bias ≈ 0 for all three). In the resting regime the TCH recovers only the independent-error floor: because true HR barely moves, the shared beat-to-beat HRV that the instantaneous devices (H10, Verity) faithfully track is stripped out as if it were common signal, so their σ̂ is biased low — H10 by −0.47 bpm (−21% of its 2.2) and Verity by −0.17 bpm — while the smoothed O2Ring, which averages that HRV away anyway, drifts slightly high (+0.07 bpm). This is the quantitative reason a non-resting session is worth more than several resting ones: it is not that resting windows are noisier, it is that they answer a subtly different (and under-stated) question.
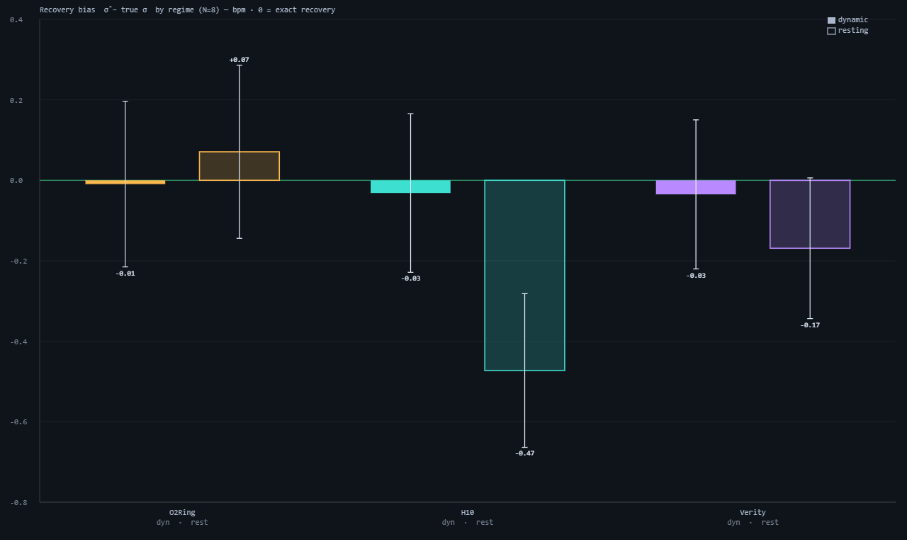
| Device | Dynamic bias | Resting bias |
|---|---|---|
| O2Ring (pulse) | −0.009 | +0.071 |
| Polar H10 (ECG) | −0.031 | −0.473 |
| Verity Sense (PPG) | −0.035 | −0.169 |
3.3 Below a few windows the uncorrelated-error assumption is uncheckable
The TCH assumes the three devices' errors are independent; a negative recovered variance is the tell that they are not. Injecting a known error correlation ρ between the H10 and Verity legs and measuring the probability that at least one window produces a negative TCH variance quantifies when that failure becomes detectable (Table 3). A clean trio (ρ=0) never produces a negative across any N — the method's specificity is intact. A small correlation (ρ=0.15) is nearly invisible: caught only ~4% of the time at a single window and still only ~53% by 20 windows. A moderate one (ρ=0.3) is caught ~55% at N=1 and almost always by a handful of windows; ρ≥0.5 is caught every time. The reading: below a few windows a correlated-error failure is statistically indistinguishable from sampling noise, so a σ quoted from one or two windows cannot certify its own central assumption — another reason to report N alongside the number.
| ρ (injected) | N=1 | N=3 | N=8 | N=20 |
|---|---|---|---|---|
| 0 (independent) | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.15 | 0.04 | 0.11 | 0.26 | 0.53 |
| 0.30 | 0.55 | 0.91 | 1.00 | 1.00 |
| 0.50 | 1.00 | 1.00 | 1.00 | 1.00 |
3.4 An anecdotal real window agrees with the simulation
The one committed real trio-window (2026-06-16/17, 7,057 simultaneous seconds) recovers σ̂ = 1.67 / 2.17 / 6.22 bpm for O2Ring / H10 / Verity — within hundredths of the planted totals the simulation uses, and the within-window block-bootstrap 95% CIs bracket those values (Table 4, Figure 3). The pairwise correlations (H10↔O2Ring r≈0.74, the rest near 0) are the resting-regime signature, and no window produced a negative TCH variance, so the independence assumption is not contradicted at the one-window level the assumption test says is uncheckable. We treat this as an anecdote rather than a validation: a single window cannot test the 1/√N law or the independence assumption, and the fully synthetic arm already answers the sample-size question on its own. (Two caveats on this one window: it spans ~2 h — longer than the simulation's 1-h windows, so its single-window CI is tighter than a 1-h N=1 cell; and its Verity σ̂ of 6.22 is this single noisy resting window, whereas the companion paper's four-window aggregate refines Verity to ≈4.0 bpm — so the planted 6.2 is a conservative high-end value. The recommendation scales with the σ ratio, so the conclusions hold either way.)
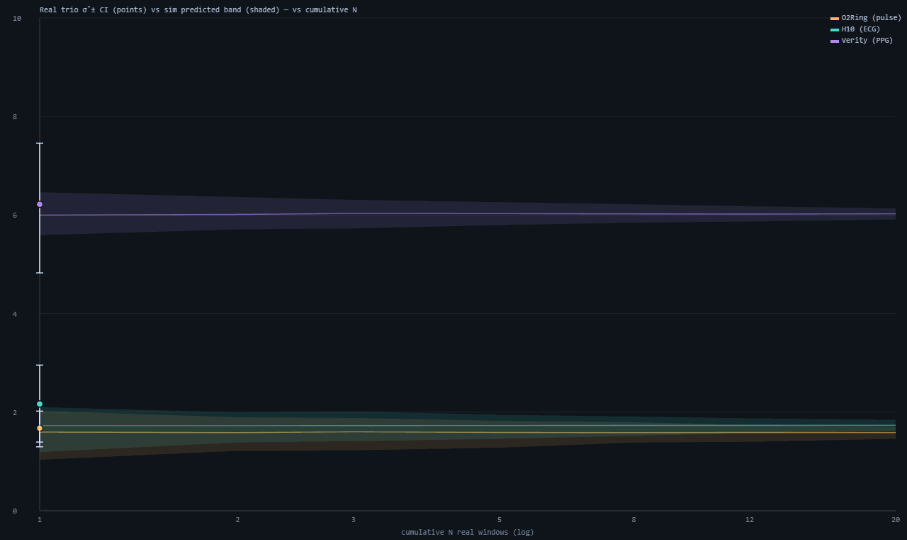
| Device | σ̂ (bpm) | within-window 95% CI | planted total |
|---|---|---|---|
| O2Ring (pulse) | 1.67 | 1.30 – 2.03 | 1.7 |
| Polar H10 (ECG) | 2.17 | 1.41 – 2.88 | 2.2 |
| Verity Sense (PPG) | 6.22 | 4.89 – 7.47 | 6.2 |
3.5 How many minutes per window? Length trades against count
The "how many windows" answer above fixes each window at one hour, too coarse for a practitioner deciding how long to wear all three devices. Sweeping the window length at a single window (N=1, dynamic regime) makes the duration cost explicit (Figure 4, Table 5). Because the 1-Hz device error is strongly autocorrelated (AR(1), φ=0.9), the effective number of independent samples grows far slower than the raw seconds, so the σ̂ CI half-width shrinks only gradually with length: a 1-minute window leaves σ̂ uncertain to ≈1.4–2.4 bpm, 10 minutes to ≈1.0 bpm, and a full 60-minute window only just reaches ±0.5 bpm — O2Ring needs even longer than 60 min to clear it. The tighter ±0.25 and ±0.15 targets are out of reach for any single window ≤ 1 h. The practical reading: ~1 hour is the floor for one window to pin σ to ±0.5 bpm; finer precision must come from more windows, not a longer one — what ultimately matters is the total co-recorded minutes of clean (dynamic) signal, split between window length and window count (the exact length×count tradeoff at a fixed total is not separately characterized here).
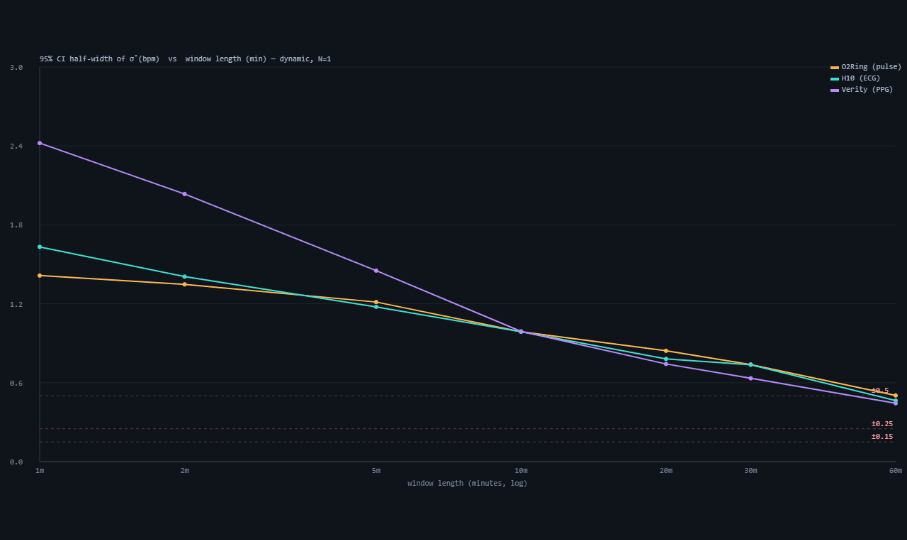
| Device | → ±0.5 bpm | → ±0.25 bpm | → ±0.15 bpm |
|---|---|---|---|
| O2Ring (pulse) | >60 min | >60 min | >60 min |
| Polar H10 (ECG) | 60 min | >60 min | >60 min |
| Verity Sense (PPG) | 60 min | >60 min | >60 min |
4. Discussion
The answer to "how much co-recording it takes to measure a sensor's error" has three parts. Precision: one clean window pins the trio to ±0.5 bpm, and tighter targets follow the ~1/√N law — ±0.25 at ~5–8 windows, ±0.15 at ~12–20 — with the worst-across-devices column the one a practitioner should plan to. Coupling: the three-cornered hat ties the corners together, so the noisy Verity leg sets a shared floor and the devices are pinned at similar absolute precision rather than the noisy one needing far more data. Regime: the dominant cost of a resting night is not variance but bias — the hat recovers only the independent-error floor and under-states the instantaneous devices, so one dynamic (exercise/recovery) session is worth several resting ones and is what makes the uncorrelated-error assumption both hold and testable. The recommendation generalizes beyond these exact devices because it scales with the true σ ratio: a noisier trio raises the shared floor and shifts every column right, but the structure — couple, then pace by the worst corner, and prefer a dynamic session — is invariant.
5. Reproducibility
- Run it: open
sensor-trio-power-analysis.html→ set trials/cell, window length, regime, and the N-grid → "Run power sweep". The σ-vs-N curves, regime panel, assumption-test table, and real overlay populate live. Exportsensor-trio-power-stats.jsonand the three figures (sensor-trio-fig1…3). - Estimator: the per-window TCH kernel and cross-window aggregation are imported unchanged from
sigma-no-reference-analysis.js— this paper adds only the synthetic trio generator and the Monte-Carlo sweep over N_windows and ρ. - Real comparison: real
ppgdex-dsp.js(PPGDSP.analyze, SQI-gated) for Verity HR from raw PPG andecgdex-dsp.js(Pan–Tompkins QRS) for the H10 gold leg; O2Ring native pulse; aligned on the Clock Contract floating-ms grid. Derivation path:SIGMA-WINDOW-DERIVATION.md. Detectors are run, not modified — no app re-bundle, no provenance change. - Config (this run): 720 Monte-Carlo trials/cell on a Web-Worker pool (
sensor-trio-worker.js— per-trial deterministic seeding, pool-size-independent and bit-reproducible; live ETA, single-instance lock, IndexedDB checkpoint/resume, cancel), window 3,600 s, AR(1) φ=0.9, N ∈ {1,2,3,5,8,12,20}, ρ ∈ {0,0.15,0.3,0.5,0.7}, targets {±0.5, ±0.25, ±0.15} bpm; planted σ 1.7 / 2.2 / 6.2. - Scope: this paper is deliberately fully synthetic; the single real window is an anecdotal comparison. Gathering 5–10 co-recorded windows (3-device + Verity raw PPG + ≥1 non-resting session) would be a separate real-validation study, not a continuation of this one.
6. Sample size & statistical power
This pilot is self-referential: its subject is sample size, on two axes. The simulation precision is governed by the Monte-Carlo trial count per cell (720 here), which fixes how finely each CI half-width and bias is itself estimated; the scientific N is the number of trio-windows, whose effect on the σ CI is the result (Table 1). The synthetic arm answers the practitioner's question directly: ~5–10 windows to pin σ to a publishable CI and make the uncorrelated-error assumption testable (Table 3 shows why: at N=1 only a gross ρ≥0.3 correlation is even visible). The one real window we hold is anecdotal — a single illustrative point, not part of that count.
| Tier | Sample size | What it buys |
|---|---|---|
| Minimum (acceptable) | 1–2 | Each device σ to ≈±0.5 bpm in a clean dynamic window; a point estimate with a within-window CI. Cannot test the uncorrelated-error assumption (only ρ≥0.3 visible). |
| Recommended | 5–10 | σ to ≈±0.25 bpm with an across-window CI; the assumption becomes checkable for moderate ρ; the resting-vs-dynamic bias is directly measurable from the real windows. |
| This run (real, anecdotal) | 1 | Single committed window (7,057 s) recovering 1.67 / 2.17 / 6.22 bpm — matches the planted totals; shown as an anecdote, not a validation set. |
| This run — simulation | 720 trials/cell | The Monte-Carlo sample size behind every number in this paper. At 720 trials/cell each σ̂, bias and CI-half is pinned to its displayed precision (MC error on a half-width ≈ ±0.02 bpm), so the window thresholds above are the estimator's answer, not sampling noise. Ran on the Web-Worker pool in ~15 s (6 cores) — the worker-count axis is free, the trio-window axis is the binding one. |
| Diminishing returns | > ~20 | CI half-widths are already <±0.15 bpm in simulation; beyond here a dynamic session (removing regime bias) is worth more than another resting window. |
Practical reading: 1 clean window to state each device σ to ±0.5 bpm, 5–10 to publish a CI and certify the method's assumption, with at least one non-resting session in the set; the simulation's own 720 trials/cell pin every reported half-width to the displayed precision.
References
- Project documentation:
CLAUDE.md(Clock Contract, evidence-grade system),VERITY-SIGMA-CORNER-BRIEF.md,SIGMA-WINDOW-DERIVATION.md, Tepna suite. - Companion method paper:
papers/sigma-no-reference.html— reference-free per-device σ via the three-cornered hat. - Companion "how many nights" template:
papers/nights-icc.html— test–retest reliability and minimum recording length. - Gray JE, Allan DW. A method for estimating the frequency stability of an individual oscillator. Proc. 28th Symp. Frequency Control. 1974:243–246 (three-cornered hat).
- Tavella P, Premoli A. Estimating the instabilities of N clocks by measuring differences of their readings. Metrologia. 1994;30(5):479–486.
- Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet. 1986;327(8476):307–310.
- Efron B, Tibshirani RJ. An Introduction to the Bootstrap. Chapman & Hall; 1993 (block bootstrap for dependent data).